
Amazon Managed Service for Apache Flink Studioを触ってみた

はじめに
コンサルティング部の神野です。
前回の「Amazon Managed Service for Apache Flinkで異常検知(Random Cut Forest)をやってみた」という記事はJavaでFlinkジョブを作成する例をご紹介しましたが、実はAmazon Managed Service for Apache Flink Studioという機能も存在しPythonやSQL、Rなどを取り扱い可能でノートブック形式でコードを書いて実行して、Streamingデータを取り扱うことができます。
今回は手を動かしながらAmazon Managed Service for Apache Flink Studioについて解説していきます。
Amazon Managed Service for Apache Flink Studioについて
Amazon Managed Service for Apache Flink Studio を使用すると、インタラクティブなノートブックで標準 SQL、Python、Scala を使用してリアルタイムでデータストリームをクエリしたり、ストリーム処理アプリケーションを構築して実行したりできます。Studio ノートブックのベースは Apache Zeppelin で、ストリーム処理エンジンとして Apache Flink が使用されています。Studio ノートブックではこれらの技術をシームレスに組み合わせて、あらゆるスキルセットのデベロッパーがデータストリームの高度な分析を利用できるようにしています。
上記、Amazon Managed Service for Apache Flink StudioについてAWS公式説明の引用です。
Apache FlinkをApache Zeppelinといったノートブック形式で実行可能となり、SQL、Python、Scalaなども取り扱い可能なマネージドサービスとなります。
Apache Zeppelinのイメージ
下記画像のようにコードを書いてインタラクティブに実行できます。イメージで言うとJupyter Notebookに近しい感じで使用できるかと思います。
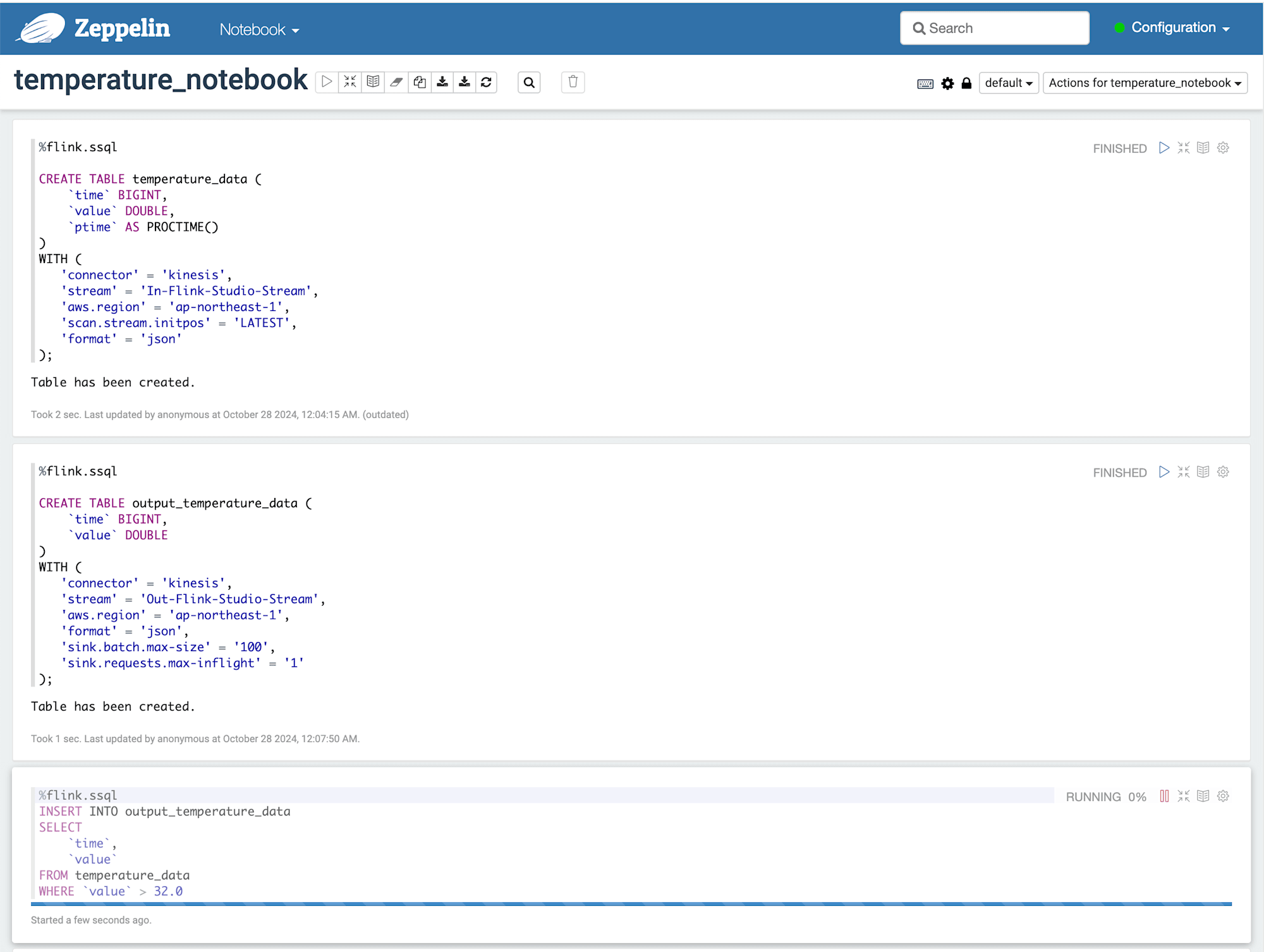
今回構築するシステム構成図
今回はシンプルにInputのStreamで流れてきたデータを少し加工もしくはフィルタリングして、OutputのStreamに出力するようにします。
環境構築
Managed Service for Apache Flink Studioを使用するにあたって下記リソースを作成していきます。
- Kinesis Stream
- Input用のStream
- 加工・フィルタリングデータが出力されるOutput用のStream
- Glue
- Database
- Managed Service for Apache Flink
- Studio ノートブック
Kinesis Stream
Input用とOutput用にそれぞれ作成します。
- Kinesisの画面でデータストリームタブを選択し、
データストリームの作成ボタンを押下
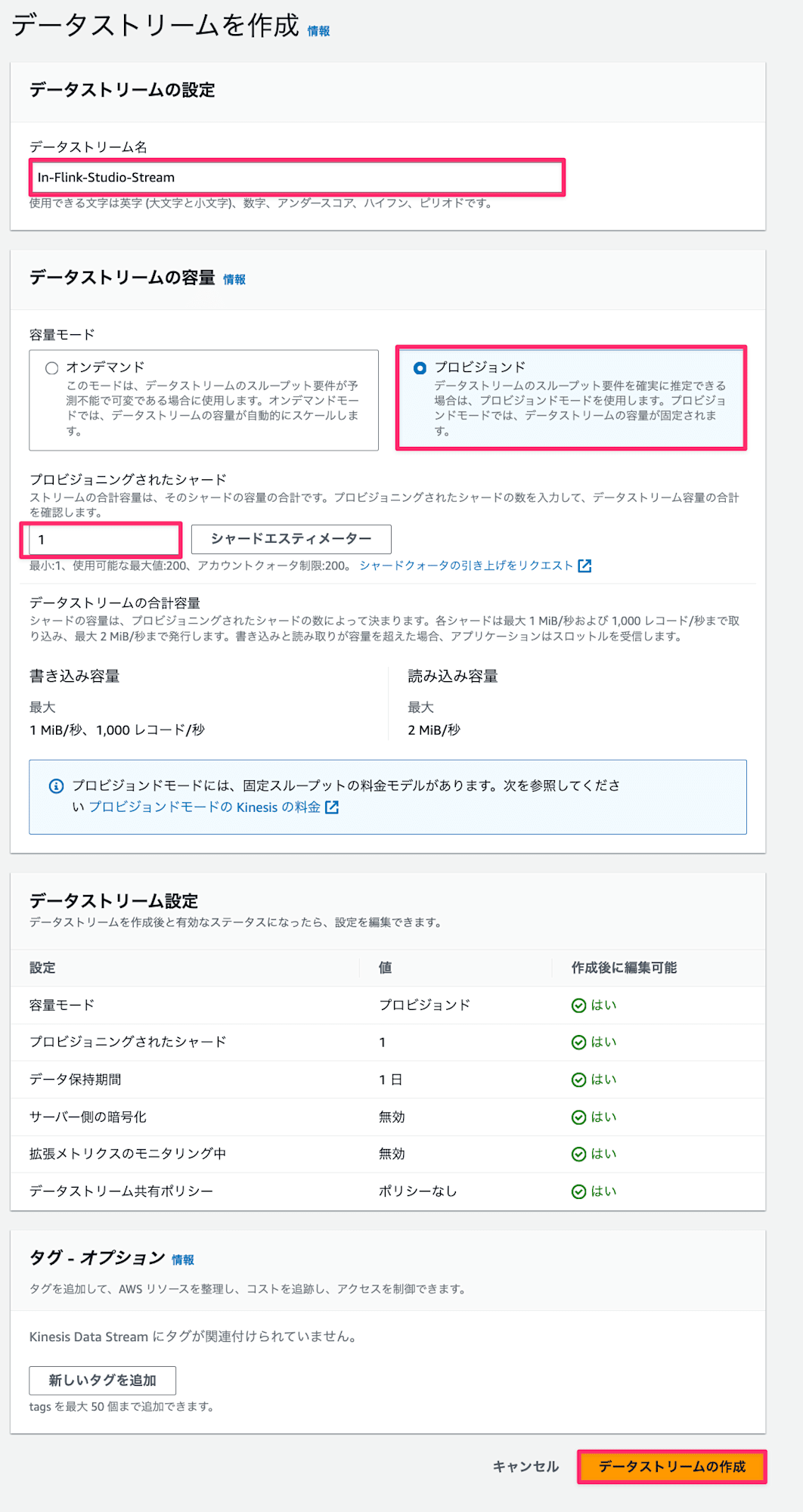
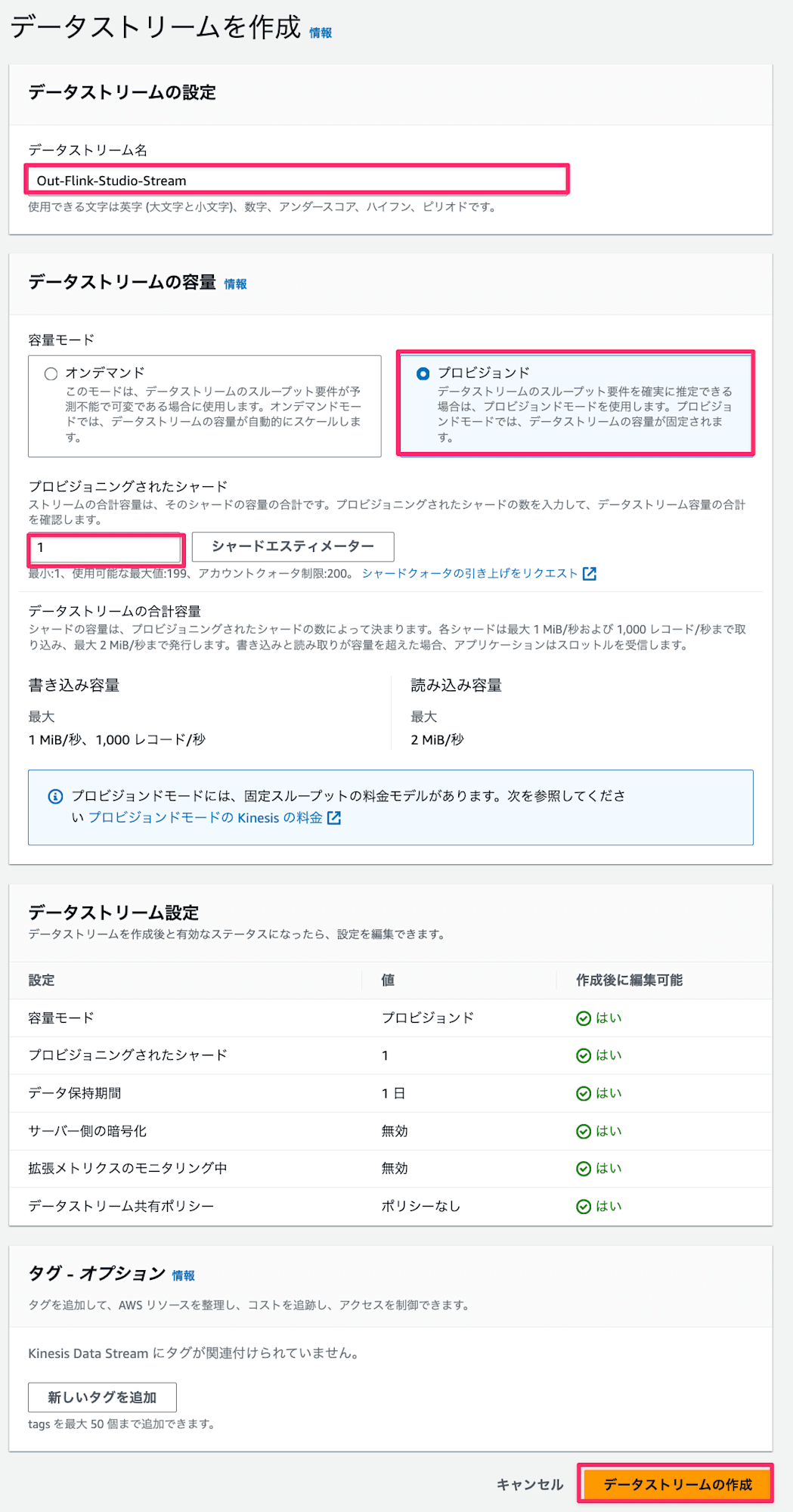
- データストリーム名は
In-Flink-Studio-Stream、Out-Flink-Studio-Streamをそれぞれ入力し、今回は検証用のため、シャード数1で容量はプロビジョンドを選択してデータストリームの作成ボタンを押下
Glue
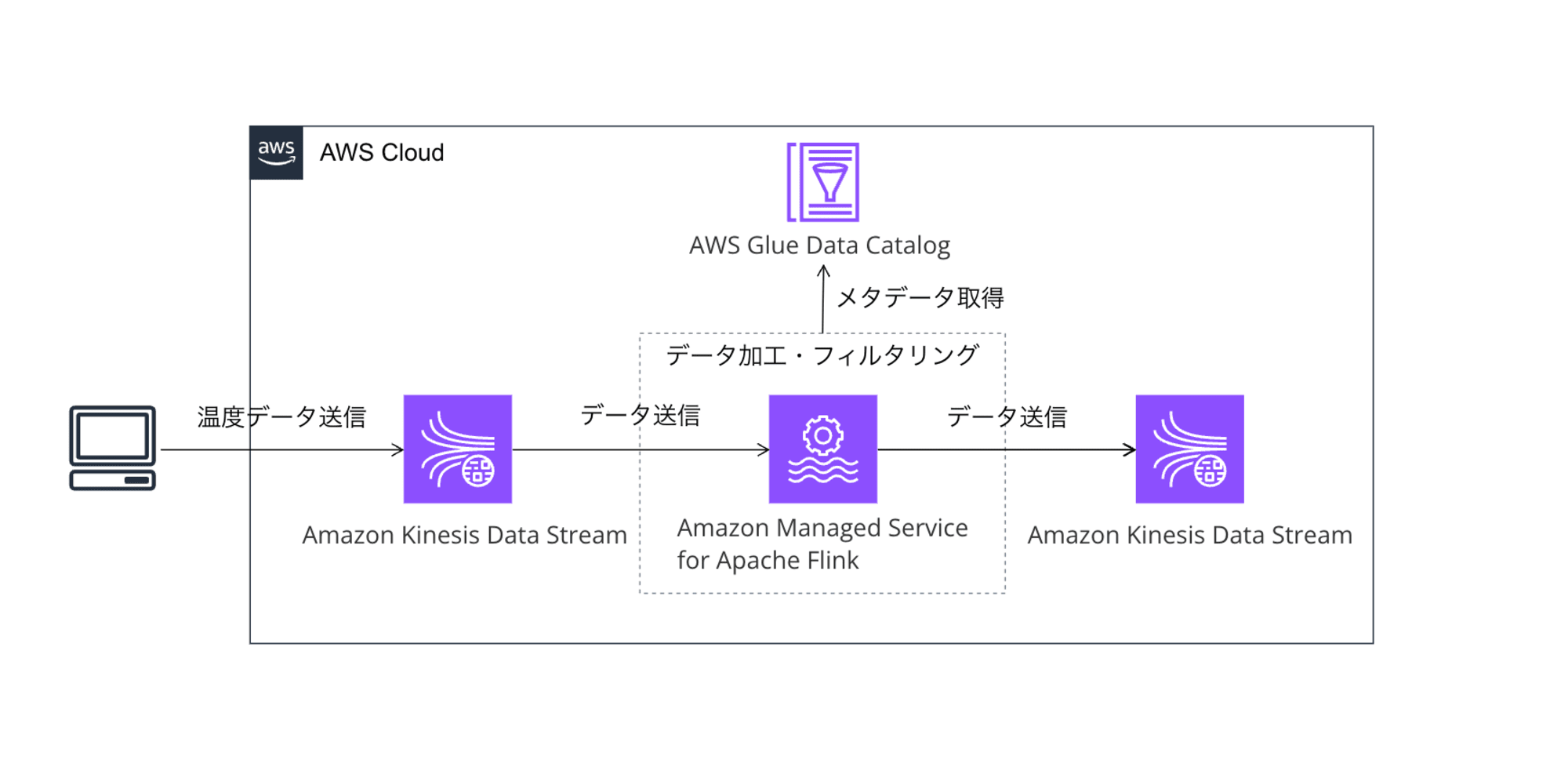
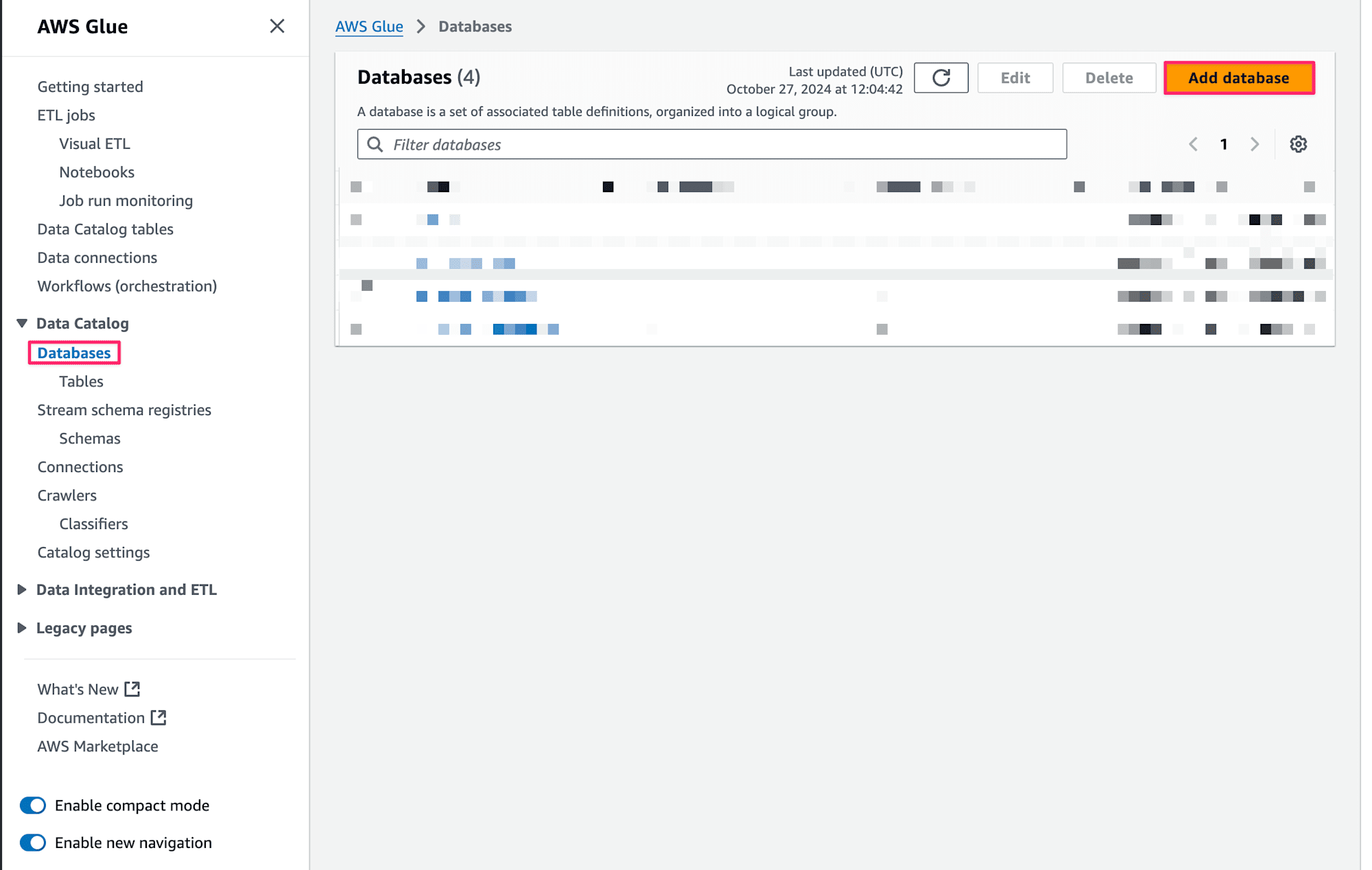
なぜGlue?と思われるかもしれませんが、Flink上でStreamデータのテーブル定義を作成するとGlueのデータカタログにメタデータが登録される仕組みとなっています。そのためFlink上から使用するデータベースを予め作成しておく必要があるためです。
Databasesタブを選択し、Add Databseボタンを押下してFlinkが使用するデータベースを作成します。
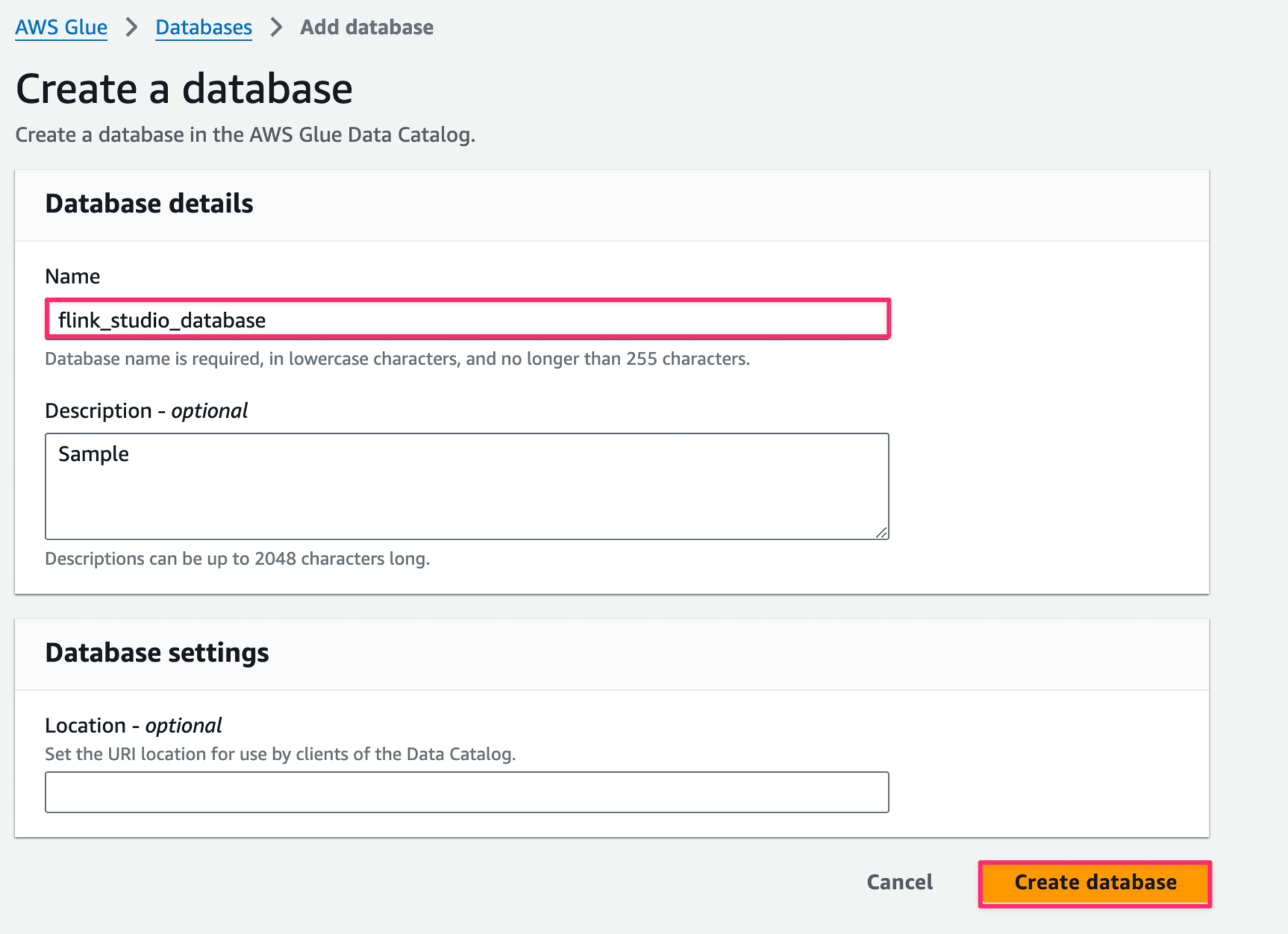
- 今回は
flink_studio_databaseといった名前をデータベースに設定して、Create databaseボタンを押下します。
Managed Service for Apache Flink Studio
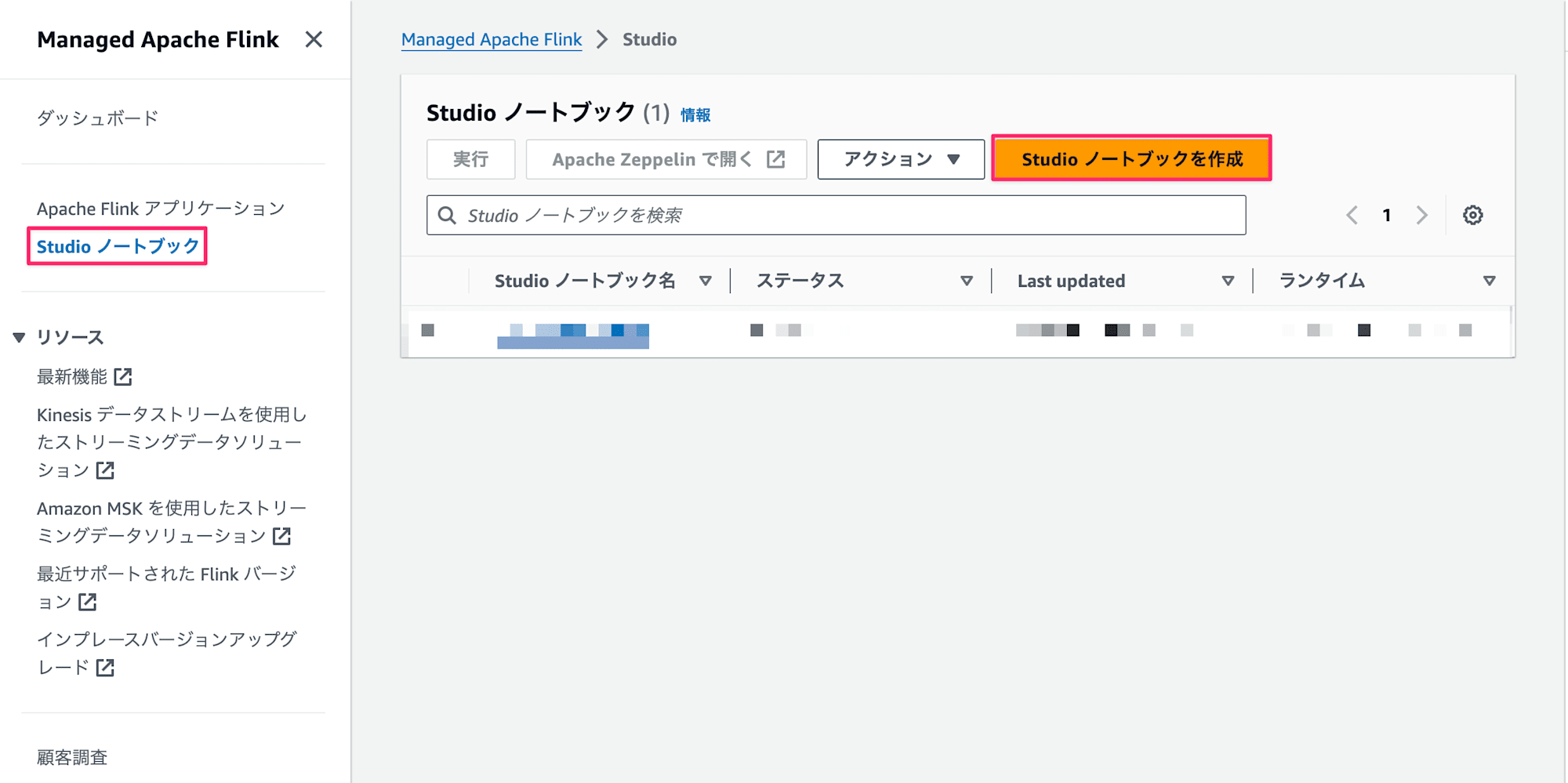
-
Studio ノートブックタブを選択してStudio ノートブックを作成ボタンを押下します。
-
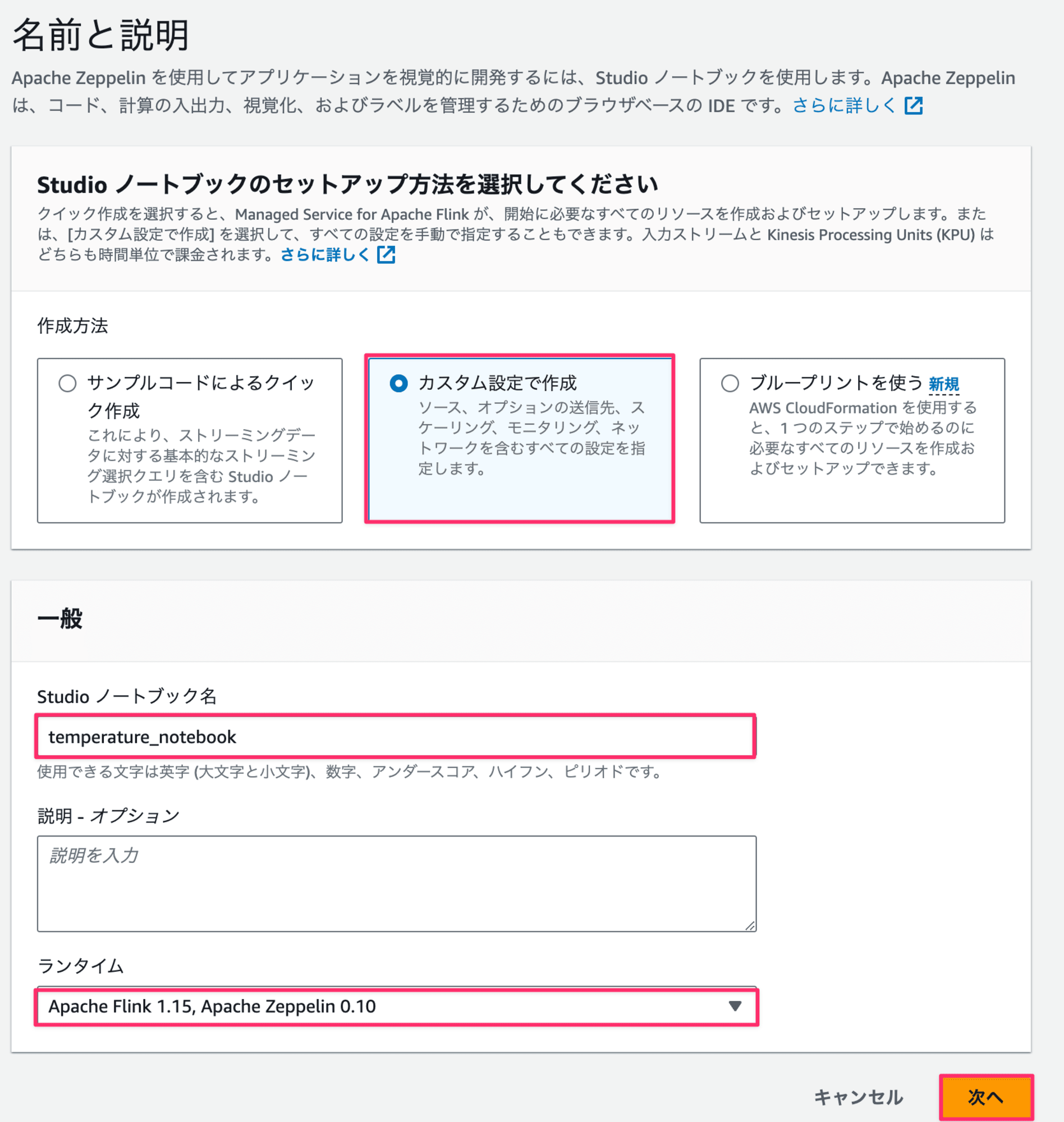
セットアップ方法を問われるので、今回は
カスタム設定で作成を選択します。
理由として1つ1つの設定項目に対して注目していくためです。- Studioノートブック名:
temperature_notebook - ランタイム
Apache Flink 1.15, Apache Zeppelin 0.10
- Studioノートブック名:
-
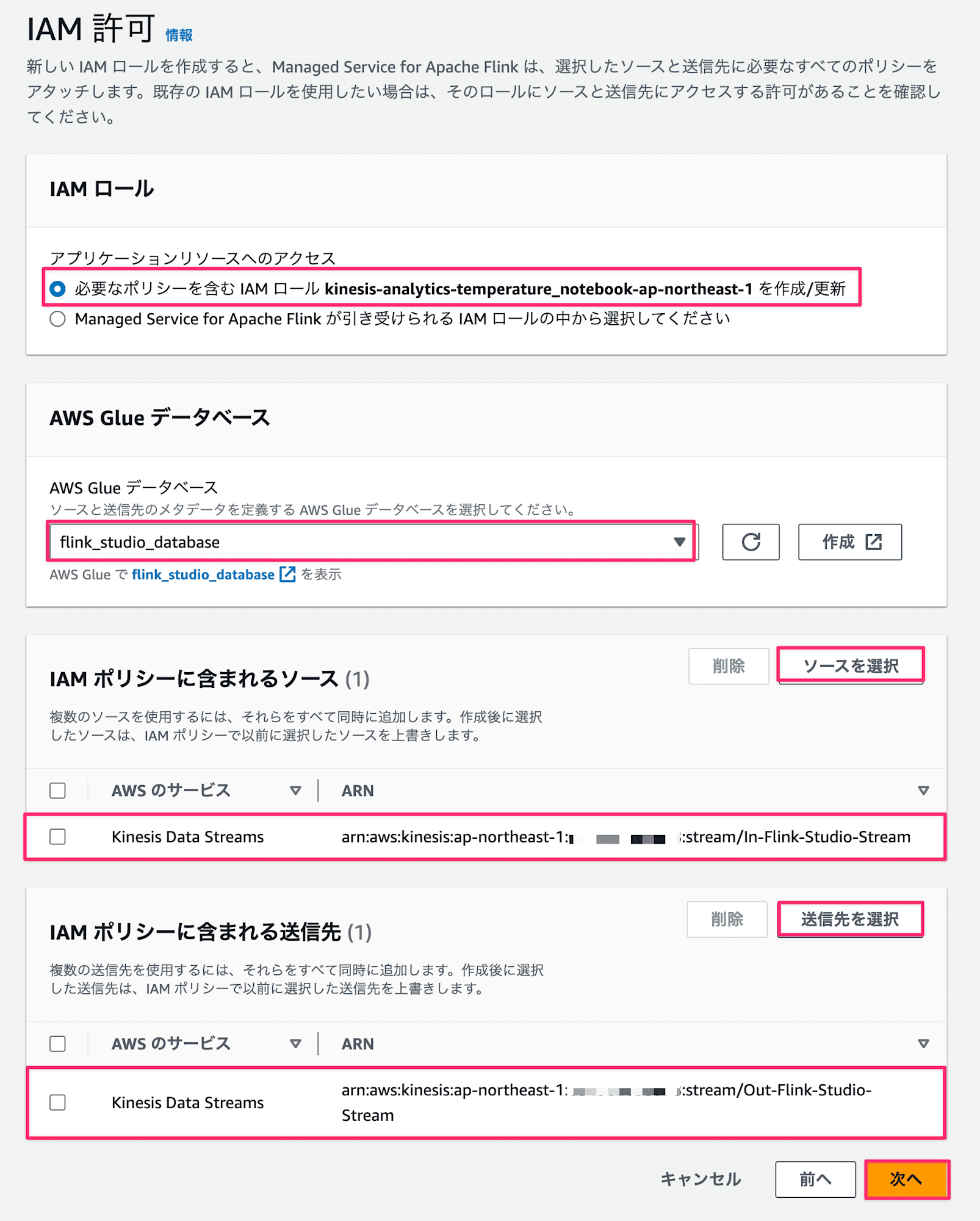
必要なIAM許可を設定します。今回はManaged Service for Apache Flink Studioでロールを作ってもらうことにし、各種リソースに対して必要な権限が自動で設定されます。
- IAM ロール:
必要なポリシーを含むIAMロールkinesis-analytics-temperature-ap-northeast-1を作成/更新 - AWS Glue データベース:
flink_studio_database - IAM ポリシーに含まれるソース:
In-Flink-Studio-Stream - IAM ポリシーに含まれるソース:
Out-Flink-Studio-Stream
- IAM ロール:
-
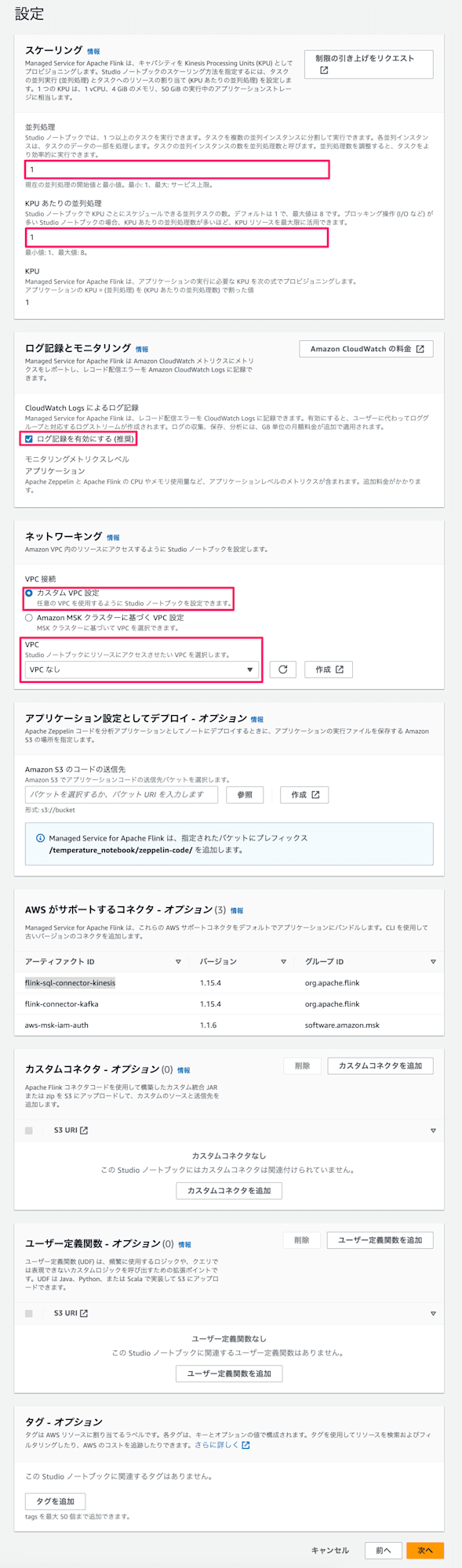
詳細な設定を定義していきます。
- スケーリング:並列処理の数を定義します。今回はサンプルのアプリケーションなので全て1を定義します。
- 並列処理:1
- KPUあたりの並列処理:1
- ログ記録とモニタリング:ログを有効にしておきます
- ログ記録を有効にする:ON
- ネットワーキング:Amazon VPCに設定するかどうかを選択します。今回はVPC内のリソースにアクセスする必要はないのでVPC無しにします。
- VPC:VPCなし
- アプリケーション設定としてデプロイ:コードを保存するS3バケットを指定します。今回は特に保存する必要はないので指定しません。
- カスタムコネクタ:データソースおよび出力先の接続用カスタムライブラリを使用するかどうか問われています。今回はKinesis Streamに接続する使用用途のみで、デフォルトで
flink-sql-connector-kinesisが提供されているため使用しません。 - ユーザー定義関数:クエリでは表現できないカスタムロジック用の関数をアップロードするか問われています。今回は使用しないのでアップロードはしません。
- スケーリング:並列処理の数を定義します。今回はサンプルのアプリケーションなので全て1を定義します。
-
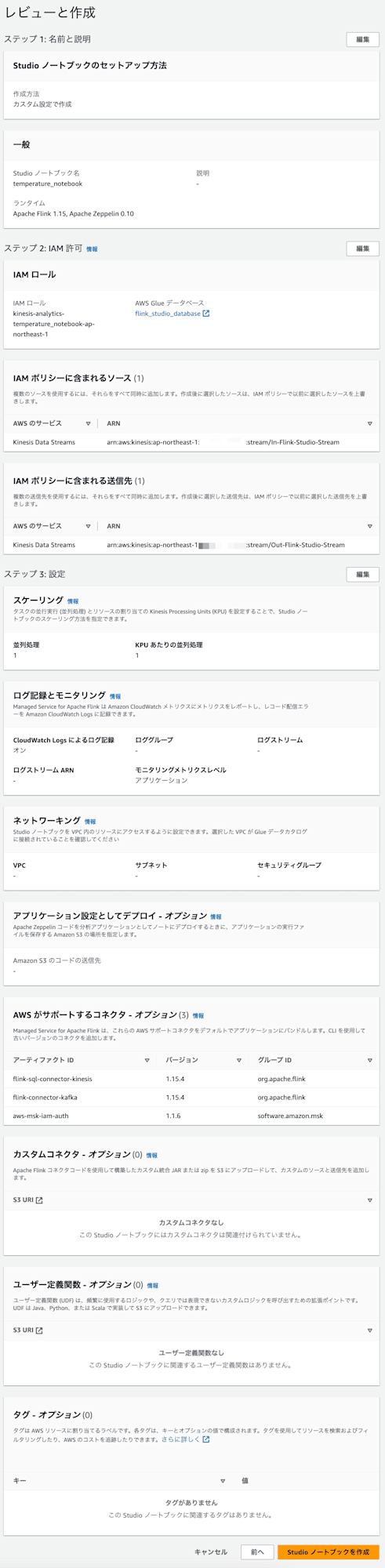
レビューと作成画面に遷移しますが、確認して特に問題なければ
Studio ノートブックを作成ボタンを押下します。
-
作成完了メッセージが表示されていればOKです!
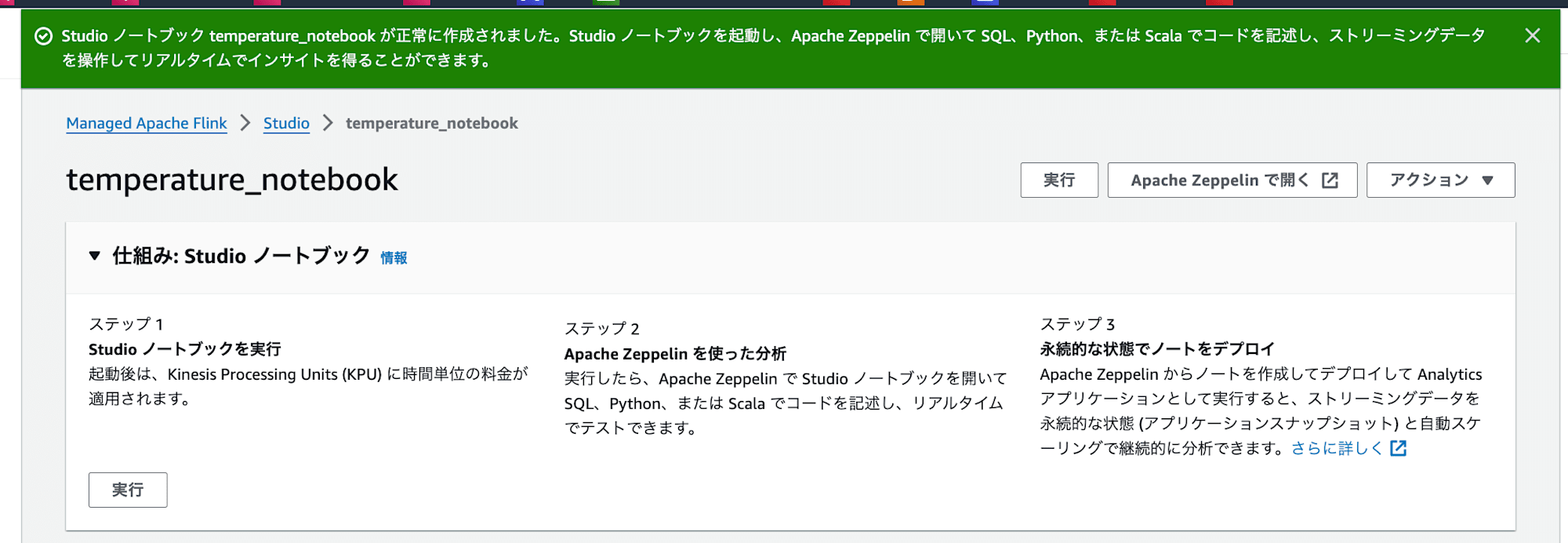
これでリソースの作成は1通り完了です!
Streamingデータの送信
温度データはCloudShellでPythonスクリプトを作成して実行しておきます。
スクリプトの概要としてIn-Flink-Studio-Streamに平均30度の温度データ&1%の確率で外れ値(15度から45度)を送信します。
import json
import boto3
import random
# InputStream名
STREAM_NAME = "In-Flink-Studio-Stream"
def get_data(time):
# 基準温度(平均30度)
base_temp = 30.0
# 通常の変動(-2度から+2度)
normal_variation = random.uniform(-2, 2)
# 1%の確率で異常値を生成
if random.random() < 0.01:
# 異常値は基準温度から大きく外れた値(例:15度から45度)
temperature = random.uniform(15, 45)
else:
temperature = base_temp + normal_variation
return {'time': time, 'value': round(temperature, 2)}
def generate(stream_name, kinesis_client):
time = 0
while True:
data = get_data(time)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey="partitionkey")
print(f"Sent data: {data}") # デバッグ用に送信データを表示
time += 1
if __name__ == '__main__':
generate(STREAM_NAME, boto3.client('kinesis', region_name='ap-northeast-1'))
下記コマンドで実行して、上記Pythonスクリプトをコピーしてpythonファイルを作成します。
nano send_temp.py
ファイルを作成し終えたら、スクリプトを実行します。
実行すると送信ログが出力されます。
python3 send_temp.py
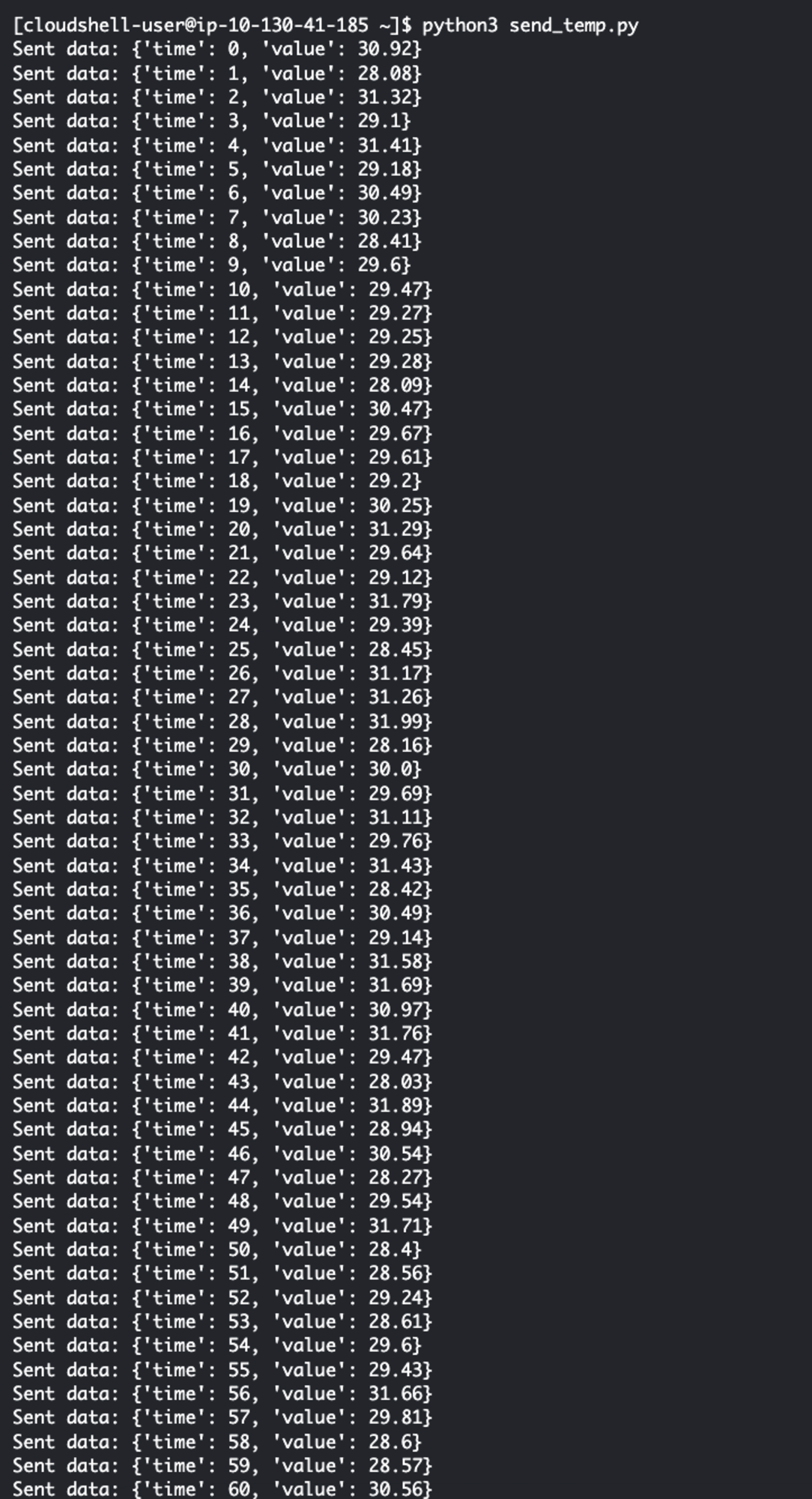
これで事前準備は完了です!
ここからはManaged Service for Apache Flink Studioの実装を進めていきます!
Managed Service for Apache Flink Studioの実行
Studio ノートブック実行
まずはStudio ノートブックを実行して起動します。
実行後はKPU単位で料金の課金が発生します。
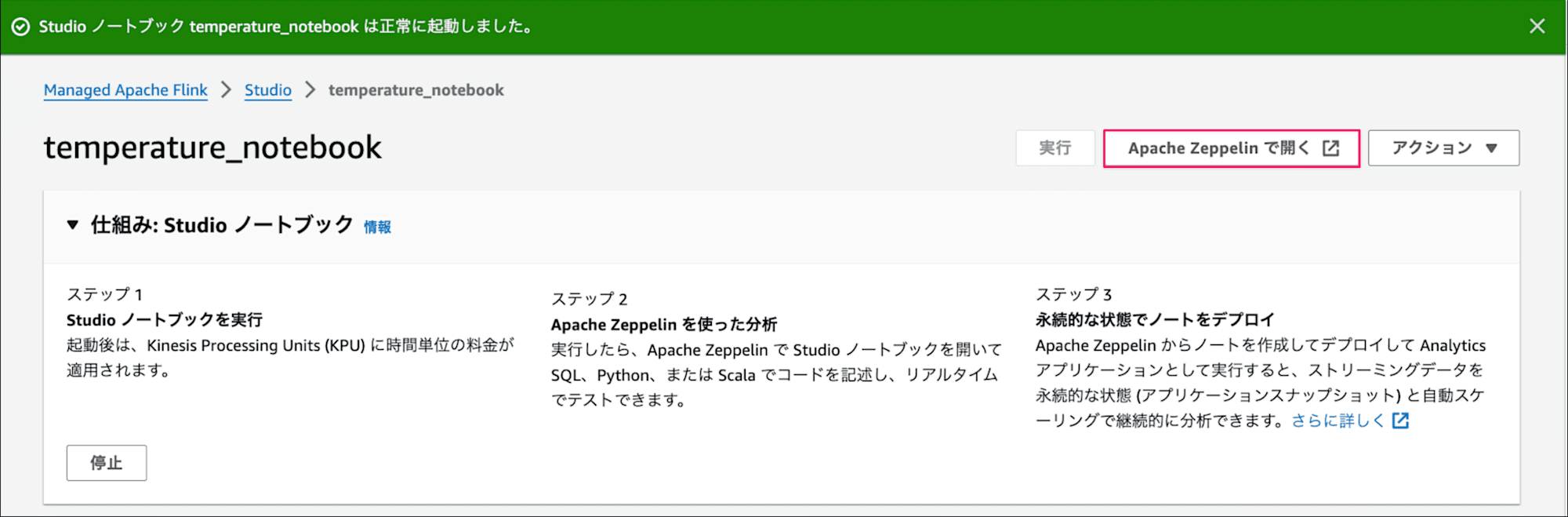
しばらく待って下記画面のように正常に起動しました。が表示されたら実行が完了です。
完了後はApache Zeppelinで開くボタンを押下して、ノートブック画面を開きます。
ノートブック作成
まずはCreate new noteリンクを押下して、新規ノートブックを作成します。
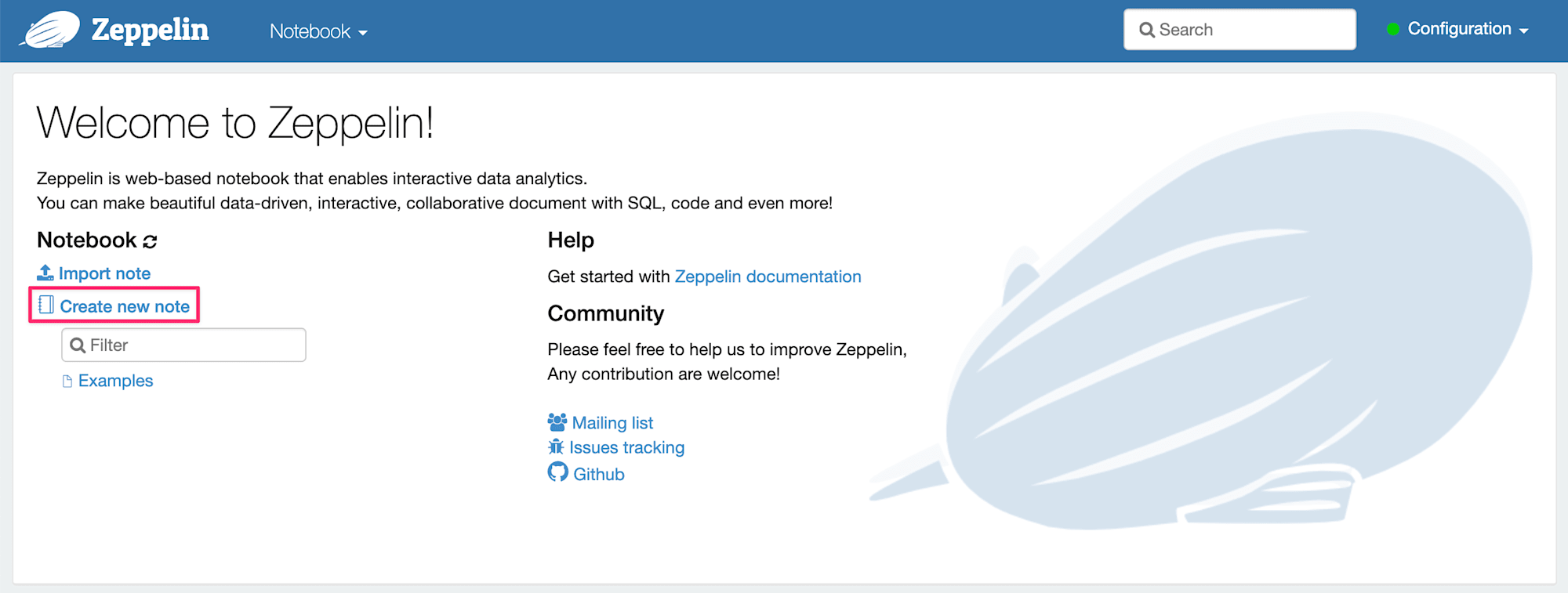
ポップアップ画面が表示されるので、
Note Name:temperature_notebookと入力してCreateボタンを押下します。
Noteブックのエディター画面に遷移します。
ここからコードを書いていきます。
テーブル作成
Input、Output用のStreamに対してそれぞれテーブルを作成します。
今回はSQLで処理を書いていきます。
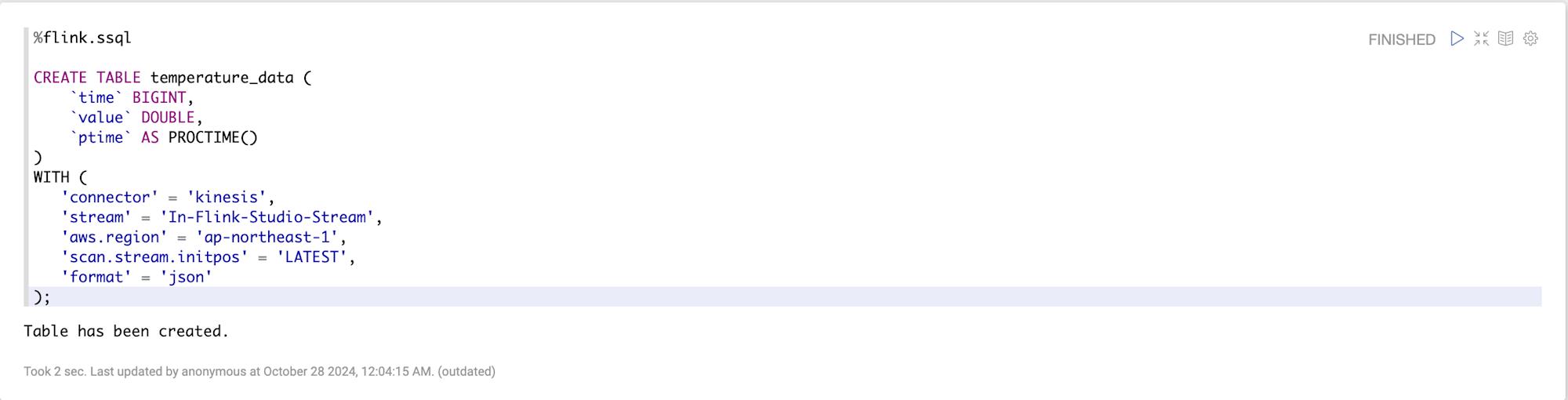
CREATE句は通常のSQL同様にテーブル定義を記載し、WITH句はStreamingデータソースとの接続方式について記載します。
-- SQLを実行する際は記載する。
%flink.ssql
-- Input Stream用のテーブル定義
CREATE TABLE temperature_data (
`time` BIGINT,
`value` DOUBLE,
`ptime` AS PROCTIME()
)
WITH (
'connector' = 'kinesis',
'stream' = 'In-Flink-Studio-Stream',
'aws.region' = 'ap-northeast-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json'
);
テーブルの設定
time,valueカラムは送信されたデータにマッピングするカラムとなります。PROCTIME()は処理した時間を取得する関数で、Timestampが返却されます。カラムptimeで保持するようにします。WITH句以降の詳細については下記表の通りです。
| 設定項目 | 設定値 | 説明 |
|---|---|---|
| connector | kinesis | 取得元のサービス |
| stream | In-Flink-Studio-Stream | 取得するStream名 |
| aws.region | ap-northeast-1 | リージョン |
| scan.stream.initpos | LATEST | テーブルがStreamから読み取る際に指定する初期位置。今回はャード内の最新データを読み取るように設定。 |
| format | json | Kinesis データ ストリーム レコードの形式。今回はjsonで送信しているため、jsonを指定 |
補足
各種設定の詳細については公式ドキュメントをご参照ください。
実行
コードを実行する際は再生ボタンみたいなアイコンをクリックして実行します。

無事実行が完了するとTable has been created.が表示されます。
同じ要領でOutput用のStreamに対してもテーブルを作成します。
テーブルのレイアウトはInputとほぼ同じでptimeカラムを削除しています。
-- Output Stream用のテーブル定義
CREATE TABLE output_temperature_data (
`time` BIGINT,
`value` DOUBLE
)
WITH (
'connector' = 'kinesis',
'stream' = 'Out-Flink-Studio-Stream',
'aws.region' = 'ap-northeast-1',
'format' = 'json',
'sink.batch.max-size' = '100',
'sink.requests.max-inflight' = '1'
);
| 設定項目 | 設定値 | 説明 |
|---|---|---|
| connector | kinesis | 送信先のサービス。kinesis以外にもfirehoseなども可能 |
| stream | Out-Flink-Studio-Stream | データを送信するStream名 |
| format | json | Kinesis データ ストリーム レコードの形式。jsonを指定 |
| sink.batch.max-size | 100 | Streamに送信する最大バッチサイズ。今回は100件のレコードを指定。 |
| sink.requests.max-inflight | 1 | 同時に処理できる未完了リクエストの最大数。今回は1を指定。 |
こちらも実行ボタンを押下してテーブルを作成します。
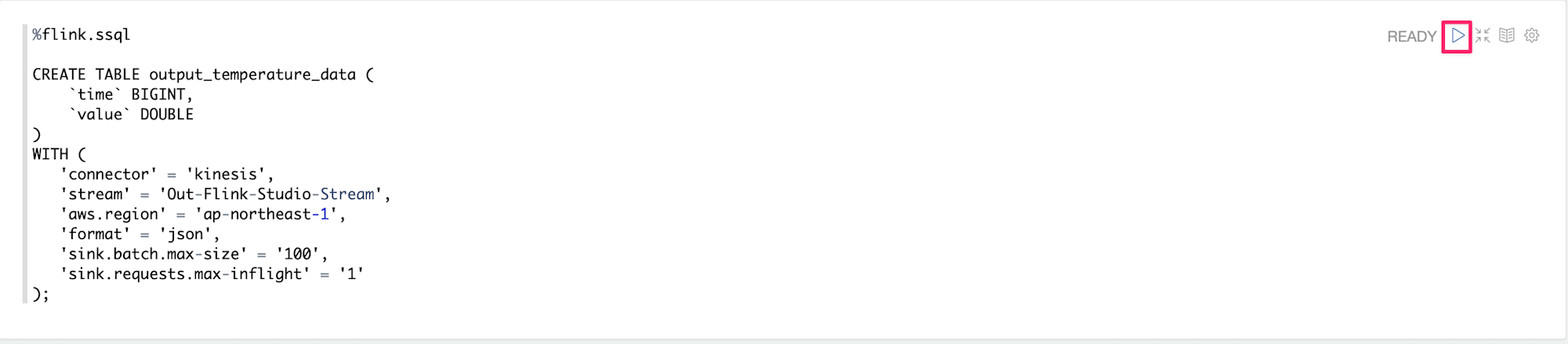
実行後

無事にTable has been createdと表示され作成が完了しましたね!
これでInput・Output用のテーブル作成が完了しました。
次は処理を書いていきます。
テーブルのフィルタリング
まずは指定の温度よりも大きい場合はOuputのStreamに流すSQLを書いて実行します。
シンプルにWHERE句で32度よりも大きい温度を抽出して、INSERTするクエリを実行します。
INSERT INTO output_temperature_data
SELECT
`time`,
`value`
FROM temperature_data
WHERE `value` > 32.0
実行すると下記のように表示されます。
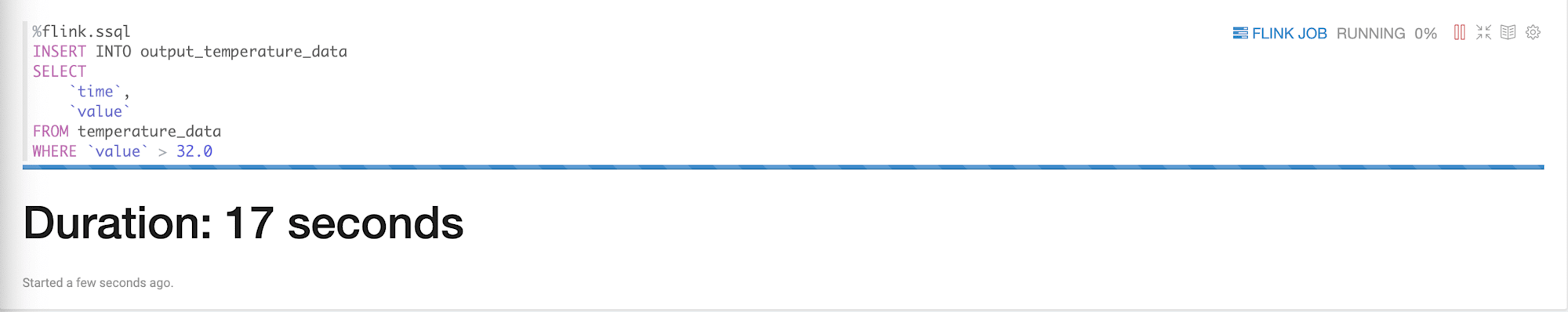
Flinkのジョブが実行している状態なので、Output用のStreamにデータが送信されているので確認してみます。
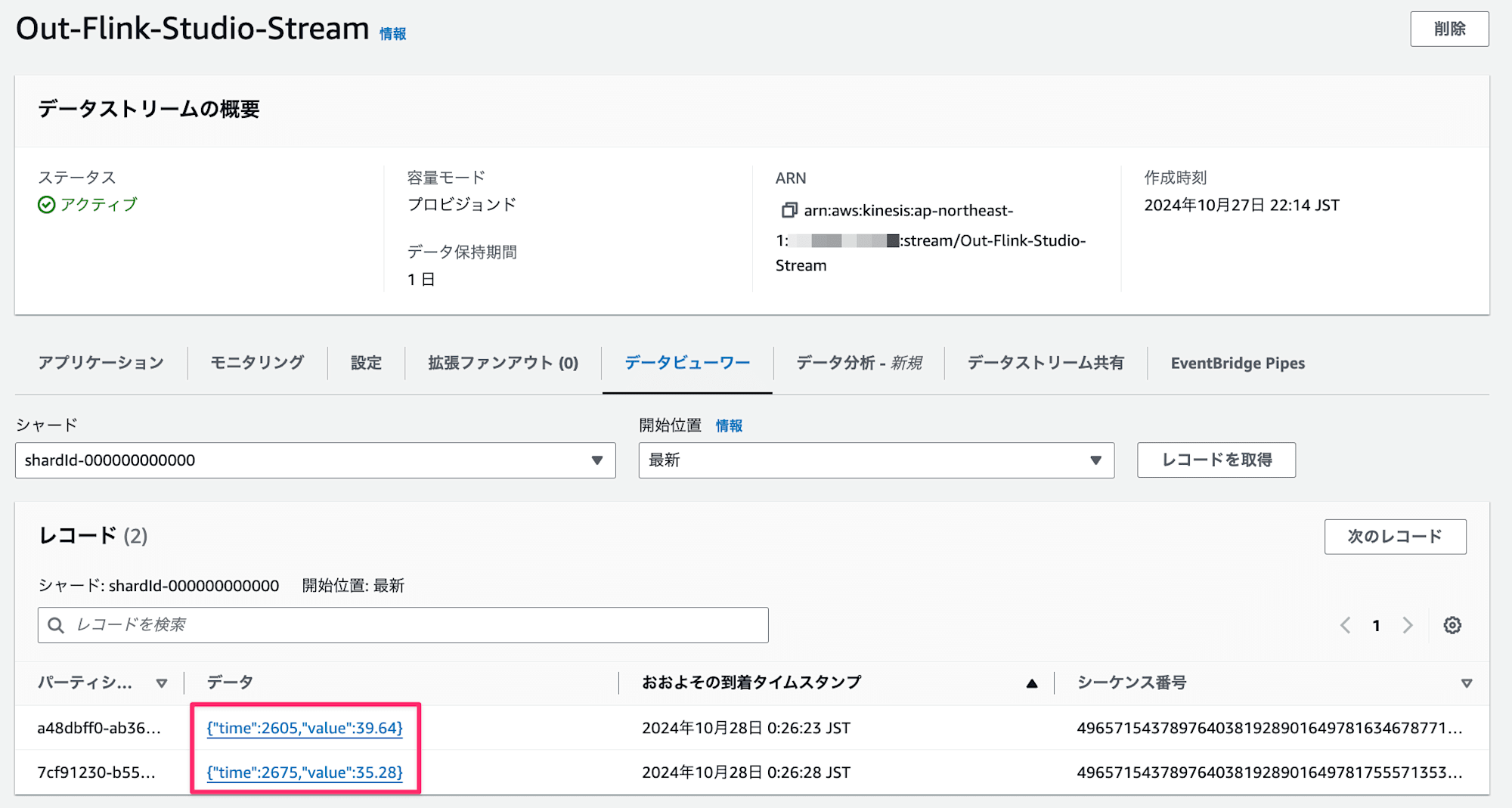
おおお、平均30度付近なので大きく外れた値が検出されていますね!
次は別のデータを送信したいので、下記停止ボタンを押下して処理を終了します。

テーブルデータの加工
次は平均10秒で集約した平均値を送信したいと思います。
TUMBLEを使用してptime到着時のタイムスタンプを10秒ごとに集約しています。
TUMBLEはタンブリングウィンドウを意味した関数で、タンブリングウィンドウのウィンドウイメージは下記を参照してもらえるといいかと思います。10秒ごとに固定のウィンドウを作成し、それぞれのウィンドウは重複しないイメージです。
実行するコード
%flink.ssql
INSERT INTO output_temperature_data
SELECT
MAX(`time`) as `time`,
AVG(`value`) as `value`
FROM temperature_data
GROUP BY TUMBLE(ptime, INTERVAL '10' SECOND);
タンブリングウィンドウのイメージ
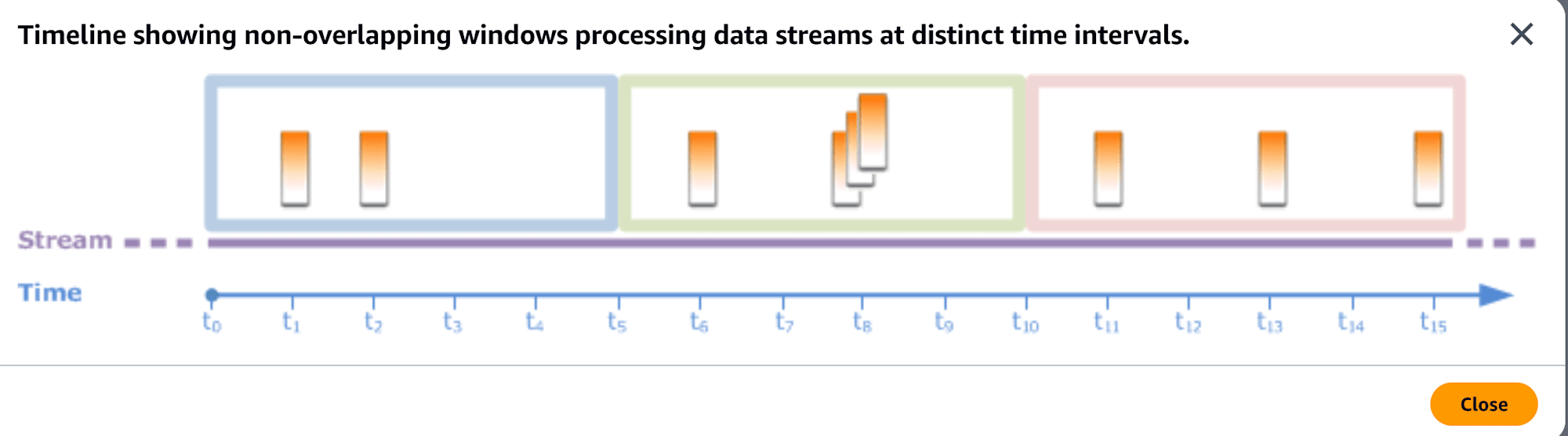 引用:Tumbling Windows (Aggregations Using GROUP BY)
引用:Tumbling Windows (Aggregations Using GROUP BY)
実行すると下記のように処理中となります。

Flinkのジョブが実行している状態なので、Output用のStreamにデータが送信されているので確認してみます。
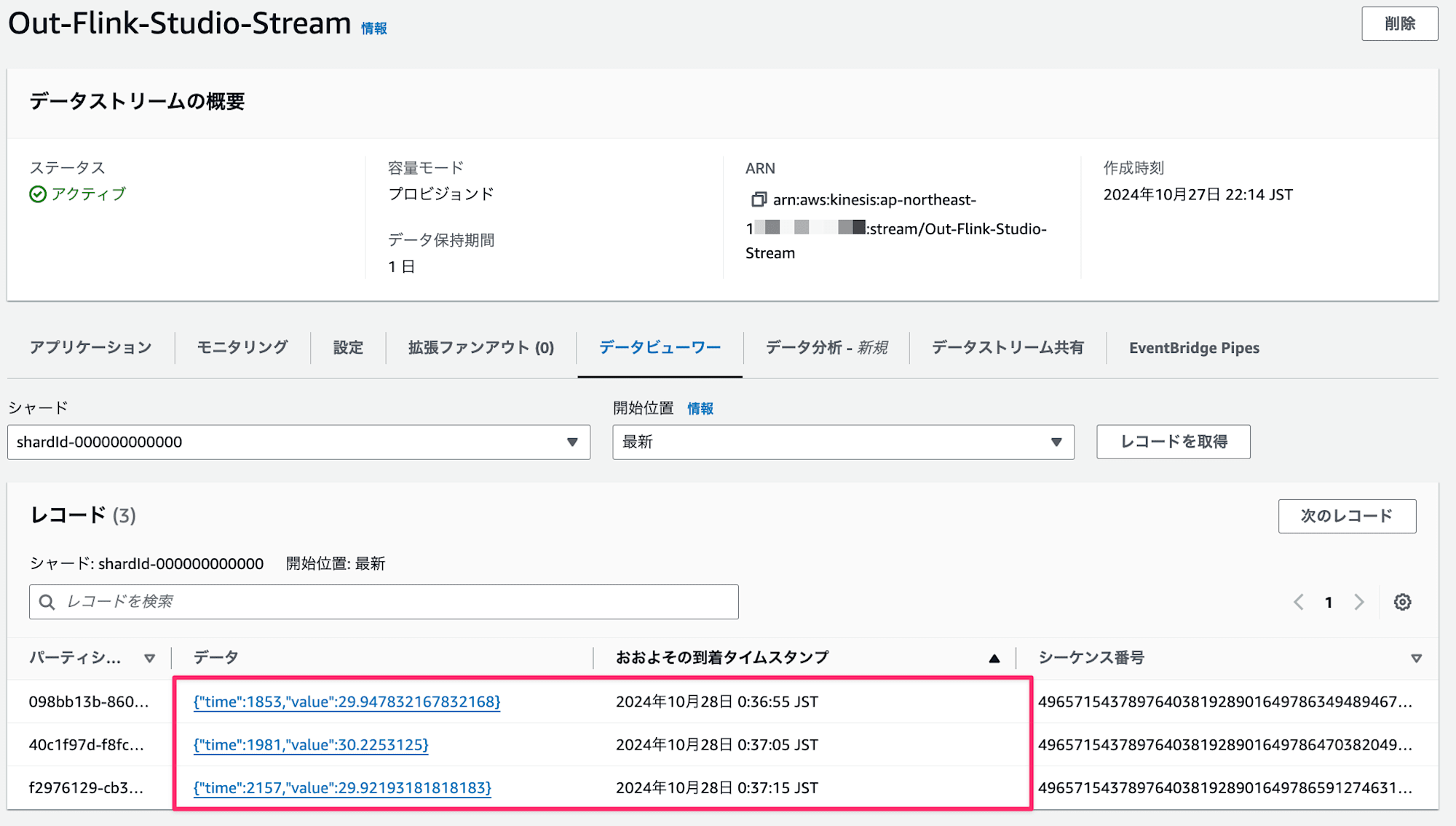
到着タイムスタンプを見ると10秒単位で集約されて送信されていますね!集約すると平均30度ぐらいになっています!
これで簡単な実装&動作確認も完了です!
おわりに
Amazon Managed Service for Apache Flink Studioはいかがでしたでしょうか。
Notebook形式でコードを書いてその場で実行できるので使いやすい印象でした!
今後はカスタムのユーザー定義関数などを使用した例なども記載していきたいと思います!
本記事が少しでも役立ったら幸いです。
最後までご覧いただきありがとうございました。


